Rilevamento presenza WiFi per Home Assistant con OpenWrt
Avevo due problemi con il rilevamento presenza di Home Assistant.
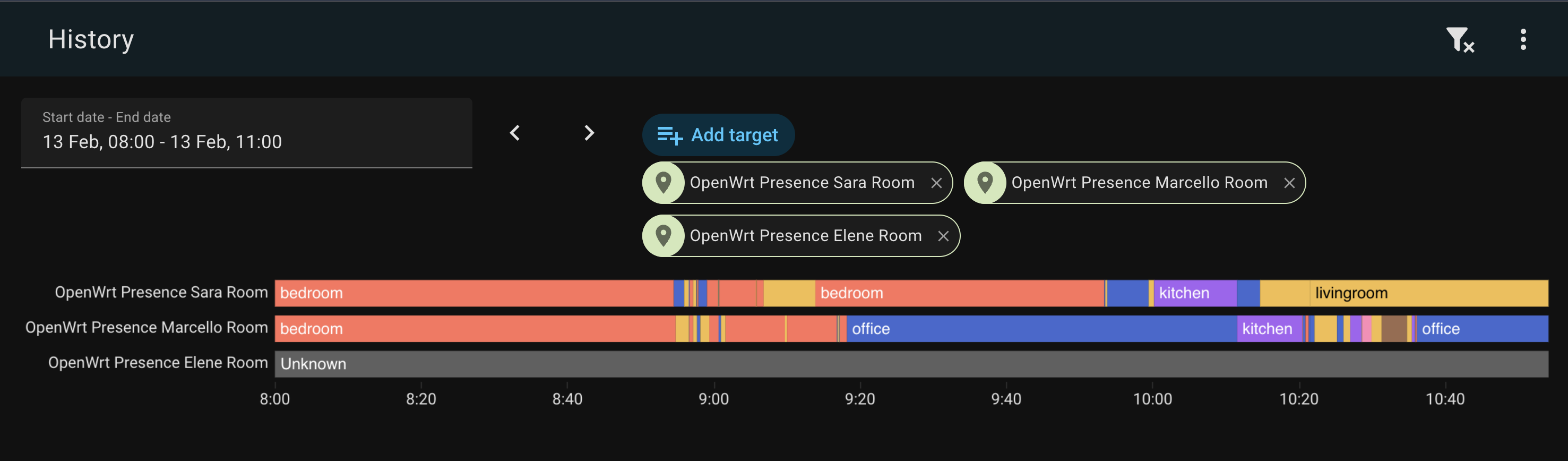
Il primo: il GPS ti dice se qualcuno è a casa, ma non dove in casa si trova. La mia casa ha sei access point OpenWrt distribuiti su tre piani. Sanno già esattamente quale telefono è connesso a quale AP in ogni momento – sono dati di presenza a livello di stanza, lì nello stack WiFi, che urlano per essere usati. Sapere chi è in quale stanza apre un’intera classe di automazioni che il GPS non può toccare: luci che ti seguono, climatizzazione per stanza occupata, una dashboard che mostra la situazione della casa a colpo d’occhio.
Il secondo: la nostra donna delle pulizie sta a casa nostra un paio di giorni a settimana. Non voglio configurarle un account HA completo, installarle l’app companion sul telefono, o avere a che fare con i permessi GPS. Ma devo sapere se è a casa – perché la mia automazione dell’allarme ha bisogno di sapere se la casa è davvero vuota prima di attivarsi. Il suo telefono si connette al WiFi. Mi basta questo.
Così ho scritto openwrt-ha-presence: una macchina a stati che scrapa le metriche RSSI direttamente dai tuoi AP OpenWrt, capisce in quale stanza si trova ogni persona in base alla potenza del segnale, e pubblica lo stato casa/fuori per ogni persona su Home Assistant via MQTT Discovery. Niente cloud, niente beacon, niente parsing di log, niente database time-series. Python, async, ~600 righe di logica effettiva.
Come funziona
OpenWrt APs → openwrt-presence → MQTT → Home Assistant
(node-exporter-lua) (state machine) (discovery) (device_tracker + sensor)
Ogni 5 secondi, openwrt-presence interroga l’endpoint /metrics su ogni AP e prende wifi_station_signal_dbm per ogni stazione associata. Quello è l’RSSI – quanto forte il segnale del tuo telefono arriva a quell’AP. Il motore poi processa lo snapshot:
- MAC visibile → CONNECTED. Stanza = AP con l’RSSI più forte.
- MAC scomparso (era visibile, ora sparito da tutti gli AP) → DEPARTING. Parte un timer di partenza.
- Timer scaduto → AWAY. La persona ha lasciato la casa.
- Ricompare prima del timeout → CONNECTED di nuovo. Timer cancellato. Bentornato.
Nodi di uscita vs interni
Non tutti gli AP sono uguali. Disconnettersi dall’AP del giardino significa qualcosa di molto diverso dal disconnettersi dall’AP della camera da letto. Il tuo telefono scompare dall’AP della camera? Probabilmente si è addormentato. Il tuo telefono scompare dall’AP del giardino? Probabilmente sei uscito.
Quindi i nodi possono essere contrassegnati come exit o interior (il default):
- Nodi exit (giardino): il device scompare → timeout breve (
departure_timeout, il mio è 120s). Se non ricompari su nessun AP, sei uscito. - Nodi interior (ufficio, camera, cucina): il device scompare → timeout lungo come rete di sicurezza (
away_timeout, default 18h). Il tuo telefono si è addormentato? Non importa. Torna quando vuoi.
Questo è opt-in. Se non contrassegni nessun nodo come exit, tutti i nodi usano departure_timeout – semplice e piatto. Ma se hai un AP all’ingresso di casa, contrassegnalo come exit: true e goditi il rilevamento rapido delle partenze senza falsi positivi dal doze del telefono sugli AP interni.
La selezione della stanza usa l’RSSI più forte. Il tuo telefono è nella stanza dove viene sentito più forte.
Per ogni persona, HA riceve:
device_tracker.<persona>_wifi—home/not_homesensor.<persona>_room—office,bedroom,kitchen, ecc.
Auto-discovered via MQTT. Zero configurazione manuale di HA.
Il percorso
Il design attuale è la terza iterazione. Arrivarci è stato… istruttivo.
Tentativo 1: eventi log di Hostapd
La prima versione parsava eventi AP-STA-CONNECTED e AP-STA-DISCONNECTED dai log di hostapd. Ogni AP spediva il suo syslog a VictoriaLogs, e il mio motore seguiva lo stream di log per gli eventi WiFi.
L’architettura era event-driven e sembrava elegante. Sulla carta.
OpenWrt APs → VictoriaLogs → openwrt-presence → MQTT → HA
(hostapd) (log store) (state machine) (discovery)
La presenza WiFi sembra banale finché non la provi davvero. Il tuo telefono si disconnette dal WiFi costantemente – roaming tra AP, risparmio energetico a schermo spento, le 37 riconnessioni giornaliere che il tuo iPhone fa per nessuna ragione al mondo. Se mappi ingenuamente “disconnessione = uscito di casa”, vieni segnato come fuori ogni volta che vai in cucina.
Così ho inventato il modello exit vs interior node:
- Nodi interni (ufficio, camera, cucina): le disconnessioni vengono completamente ignorate. Solo le connessioni aggiornano la stanza corrente.
- Nodi exit (giardino): la disconnessione avvia un timer di partenza. Se non ti riconnetti a nessun AP entro 120 secondi, sei uscito.
Questo ha eliminato il 99% del rumore. E poi è arrivata la produzione.
Clock skew: una storia d’amore
Quattro dei sei AP non avevano NTP abilitato. L’AP del giardino – il nodo exit, quello i cui timestamp contano davvero per il rilevamento delle partenze – era indietro di 3 minuti e mezzo. Questo significava che il timeout di partenza di 2 minuti era effettivamente negativo. Le persone che erano chiaramente uscite non venivano mai segnate come assenti perché i timestamp dicevano che non erano state via abbastanza a lungo. Chiedimi come l’ho scoperto.
Ordinamento del backfill
All’avvio, il motore faceva backfill delle ultime 4 ore da VictoriaLogs per ricostruire lo stato. Problema: VictoriaLogs restituisce i risultati raggruppati per log stream (per-AP), non in ordine cronologico globale. Quindi se l’ultimo stream restituito è dall’ufficio, finisci nell’ufficio – anche se l’evento più recente era dal soggiorno. Fix: ordinare tutti gli eventi di backfill per timestamp prima di processarli. Semplice, una volta che smetti di fidarti dell’API per farlo al posto tuo.
Il telefono di Sara: 3.821 eventi in 10 giorni
Questo è stato il migliore. Mia moglie Sara ha un iPhone 16 Pro. Io ho un iPhone 16 Pro Max. Stessa casa, stessi AP, stessa rete. Eppure il suo telefono stava generando 3,4 volte più eventi WiFi del mio. Il 78% di tutti i suoi eventi erano flapping – cicli rapidi di connessione/disconnessione sullo stesso AP.
La diagnosi: due AP (ufficio al primo piano, soggiorno al piano terra) impilati verticalmente con entrambi a 23 dBm – potenza di trasmissione massima. Attraverso un soffitto italiano in cemento da 2,7m, il telefono di Sara vedeva una potenza del segnale quasi identica da entrambi gli AP e rimbalzava tra di loro ogni 1-3 secondi. La sua peggior serie di oscillazioni: 161 connessioni, rimbalzando avanti e indietro come una pallina da ping-pong.
802.11r Fast Transition stava peggiorando le cose – il roaming sotto il secondo significava che il telefono poteva rimbalzare più velocemente di quanto potesse fare con la ri-autenticazione completa.
Fix: ho ridotto la potenza TX da 23 a 14 dBm sugli AP interni, e ho configurato le soglie min_connect_snr e min_snr di usteer per impedire le associazioni deboli. Il telefono non può rimbalzare tra AP se l’AP si rifiuta di parlargli.
L’approccio event-based funzionava, alla fine. Ma era fragile in modo fondamentale: dipendeva dal fatto che gli eventi di log venissero emessi e consegnati. Se un AP non genera mai un disconnect (perché il telefono è uscito dal raggio d’azione piuttosto che dissociarsi in modo pulito), il motore non lo sa mai. Servono un timeout di sicurezza, la distinzione dei tipi di nodo, la gestione del clock skew, l’ordinamento degli eventi di backfill, sopravvivere ai singhiozzi della pipeline di log. Sono un sacco di “ti serve” per un rilevatore di presenza.
Tentativo 2: VictoriaMetrics + metriche RSSI
Stavo già facendo girare prometheus-node-exporter-lua su ogni AP per le metriche di sistema (CPU, memoria, le solite). Il collector wifi_stations espone wifi_station_signal_dbm per ogni stazione associata – RSSI, lì, già raccolto da Telegraf e salvato in VictoriaMetrics ogni 5 secondi.
Quindi ho riscritto il motore per interrogare VictoriaMetrics invece di parsare log. Niente più eventi – solo snapshot RSSI periodici. Selezione della stanza per segnale più forte invece di connessione più recente. Il modello exit/interior node è rimasto, ora controllando quale timeout applicare quando un device spariva da tutti gli AP. Molto più pulito.
Ma qualcosa non andava. Il rilevamento sembrava… lento. Quando camminavo da una stanza all’altra, il cambio di stato ci metteva un’eternità. Test di cammino lo confermavano: il fix max_inactivity sul driver WiFi funzionava perfettamente – l’AP cancellava il mio telefono dalla sua lista di associazione in 12 secondi. Ma VictoriaMetrics era 29 secondi indietro. Il telefono appariva nell’assoclist di albert alle 11:30:21, ma VictoriaMetrics non lo mostrava fino alle 11:30:50.
Ventinove secondi. Non è un errore di arrotondamento. È l’intera pipeline Telegraf → VictoriaMetrics che aggiunge latenza che non potevo eliminare.
E poi ho trovato la pistola fumante nei log di Telegraf:
[outputs.http] did not complete within its flush interval
[outputs.http] Metric buffer overflow; 25297 metrics have been dropped
Venticinquemila metriche, droppate. Telegraf si strozzava con il volume di metriche da sei AP (stazioni WiFi, statistiche di sistema, interfacce di rete – si accumula), e l’output HTTP verso VictoriaMetrics non ce la faceva. I dati RSSI erano stantii prima ancora di raggiungere VictoriaMetrics.
Avrei potuto ottimizzare gli intervalli di flush, aumentare la dimensione dei buffer, aggiungere una seconda istanza di Telegraf. Ma quello significa curare il sintomo. La vera domanda era: perché sto facendo passare dati critici per la presenza attraverso una pipeline di metriche general-purpose?
Tentativo 3: eliminare l’intermediario
I dati che mi servono sono già lì su ogni AP – wifi_station_signal_dbm, esposti a http://ap-hostname:9100/metrics in formato testo Prometheus. Stavo aggiungendo un’intera pipeline TSDB tra il mio motore di presenza e un semplice endpoint HTTP che è già in esecuzione.
Quindi ho buttato via VictoriaMetrics come data source e ho scritto ExporterSource: un semplice client HTTP async che scrapa ogni AP direttamente, in parallelo, ogni 5 secondi. Niente Telegraf. Niente VictoriaMetrics. Niente latenza di pipeline. Niente buffer overflow. Solo sei HTTP GET e una regex.
La pipeline è passata da:
AP → Telegraf → VictoriaMetrics → openwrt-presence
(scrape 5s) (flush 10s) (query 30s)
A:
AP → openwrt-presence
(scrape 5s)
Il rilevamento è ora limitato solo dall’intervallo di polling. Cammini dall’ufficio alla camera? Il prossimo poll a 5 secondi lo cattura. Esci di casa? 120 secondi di silenzio e sei segnato come assente. Niente eventi da perdere, niente log da parsare, niente pipeline che trabocca, niente timestamp da ordinare. Solo: “Vedo il tuo telefono su questo AP con questa potenza del segnale. Non lo vedo più. Sono passati 2 minuti. Sei andato.”
Il codice è diventato più semplice. Niente logica di ordinamento eventi, niente backfill, niente preoccupazioni di clock skew, niente connessioni in streaming. Il motore processa snapshot, non eventi. La source scrapa endpoint, non API di log. Il modello exit/interior node guida ancora la logica dei timeout – ma ora è solo questione di quale timeout applicare quando un MAC sparisce, non quali eventi ignorare. 74 test, tutti di pura logica.
Il monitor
Per il debug, volevo un pretty-print CLI in tempo reale. docker container logs eve -f ti dà JSON grezzo, che non è… divertente. Quindi c’è un monitor integrato che legge JSON dallo stdin e lo renderizza con colori ANSI:
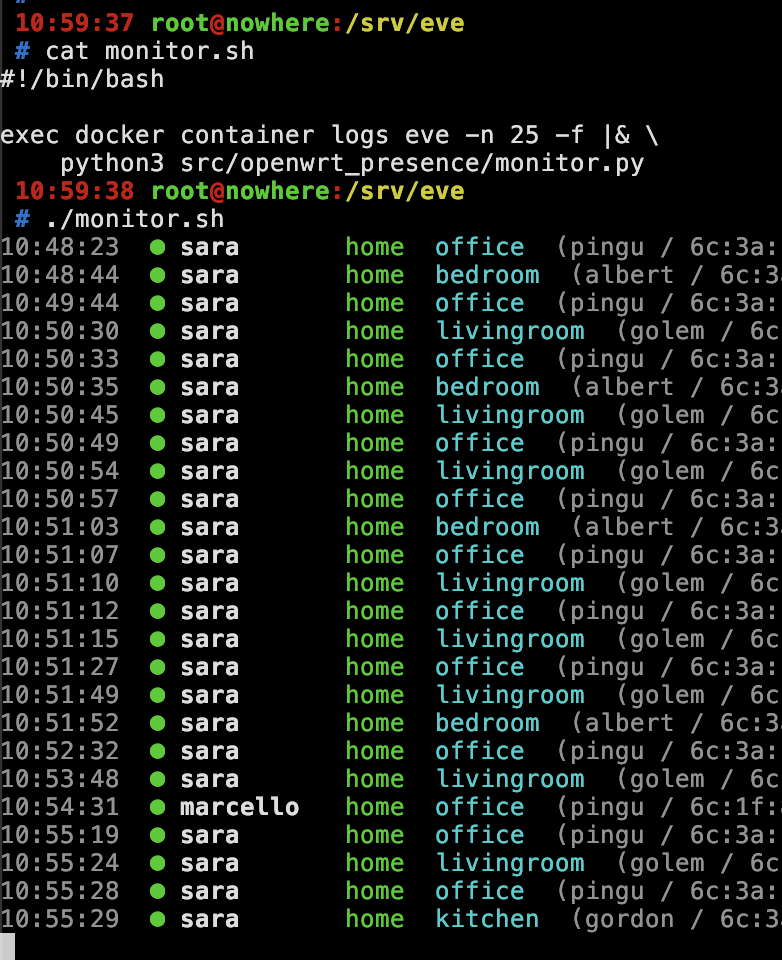
Pallino verde per gli arrivi, rosso per le partenze, nomi delle stanze in ciano, valori RSSI nei dettagli. Pura stdlib, zero dipendenze, gira direttamente con python3.
Automazione dell’allarme
Il prurito originale: attivare l’allarme quando tutti escono. “Tutti” include la donna delle pulizie, che non ha l’app companion di HA – il suo WiFi tracker è l’unico segnale di presenza che ho per lei. L’automazione controlla lo stato WiFi per tutte le persone tracciate, trattando unknown e unavailable come “non a casa” (perché se il tracker non ha mai riportato, la persona non è sicuramente confermata in casa):
automation:
- alias: "Arm alarm when everyone leaves"
trigger:
- platform: state
entity_id:
- device_tracker.alice_wifi
- device_tracker.bob_wifi
- device_tracker.charlie_wifi
to: "not_home"
condition:
- condition: state
entity_id: device_tracker.alice_wifi
state: ["not_home", "unavailable", "unknown"]
- condition: state
entity_id: device_tracker.bob_wifi
state: ["not_home", "unavailable", "unknown"]
- condition: state
entity_id: device_tracker.charlie_wifi
state: ["not_home", "unavailable", "unknown"]
action:
- service: alarm_control_panel.alarm_arm_away
target:
entity_id: alarm_control_panel.home_alarm
Il dettaglio unavailable / unknown conta. La donna delle pulizie viene due volte a settimana – quindi tra una visita e l’altra, il suo tracker è a unknown (mai visto) o not_home (ultimo avvistamento giorni fa). Senza quegli stati extra nella condizione, l’automazione non scatterebbe mai quando lei non c’è. Chiedimi come lo so.
E ora?
Niente. Funziona. Tre architetture dopo, questa tiene. 74 test, deploy Docker Compose, gira sul mio server con rilevamento in meno di 5 secondi. Il codice è con licenza MIT.
Sorgente: github.com/vjt/openwrt-ha-presence
Buon divertimento!