wifi-dethrash: trovare e risolvere il thrashing WiFi mesh su OpenWrt
Tutto è cominciato con il rilevamento presenza WiFi. Avevo costruito un sistema che traccia in quale stanza si trova ognuno scrapando l’RSSI dai miei AP OpenWrt. Funzionava – ma le assegnazioni delle stanze continuavano a sfarfallare. Cucina. Ufficio. Cucina. Ufficio. Tre volte in dieci secondi. La macchina a stati era a posto. Il WiFi no.
La mia rete domestica ha sei AP OpenWrt su tre piani, due SSID – Mercury su 5 GHz, Saturn su 2,4 GHz – tutti con 802.11r per il roaming veloce. Vista da fuori, sembra una mesh fatta bene. Vista da dentro, un telefono rimbalzava tra access point 129 volte in 24 ore.
Non lo sapevo finché non ho costruito lo strumento per vederlo.
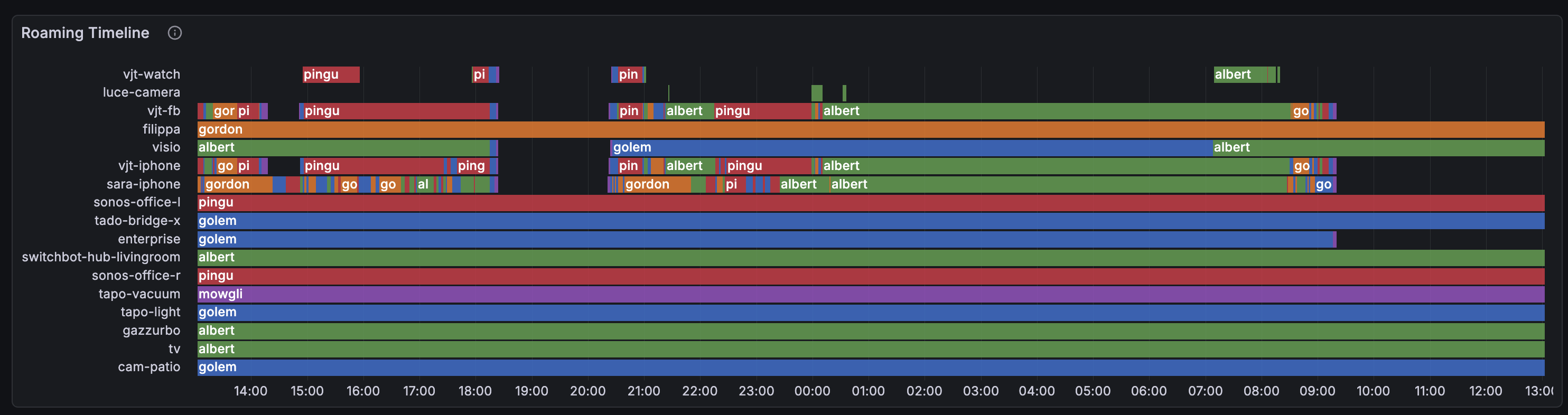
Ogni riga è un client WiFi, il colore mostra a quale AP è connesso. I client sani mostrano barre lunghe e piene. Quelli malati sembrano pali da barbiere. Vedi sara-iphone? Quella striscia arcobaleno sono 129 connessioni in 24 ore – il telefono cammina in una zona di overlap tra due AP dove entrambi hanno un segnale circa uguale (e orrendo).
Il problema che non puoi vedere
Il roaming WiFi è invisibile. Il tuo telefono mostra tutte le tacche, Netflix bufferizza un attimo, e tu dai la colpa alla connessione internet. Ma quello che è successo davvero è che il tuo telefono si è disconnesso da un AP, ha scansionato le alternative, ne ha scelto un altro con un segnale marginalmente diverso, si è associato, autenticato, e ha ricominciato lo streaming – tutto in meno di un secondo se 802.11r funziona, diversi secondi se non funziona.
Fallo 15 volte in 2 minuti tra due AP che hanno entrambi un segnale schifoso, e ottieni quello che chiamo thrashing: rimbalzi rapidi e inutili tra AP che ammazzano il throughput e sprecano airtime.
Il problema è che nessuno degli strumenti standard mostra questo. iwinfo ti mostra uno snapshot. logread mostra eventi individuali. Ma per vedere il pattern – quali client rimbalzano, tra quali AP, quanto spesso, e perché – devi correlare dati nel tempo, tra AP, e tra sorgenti di dati diverse.
La pipeline di raccolta
Prima di arrivare allo strumento vero e proprio, una parola sull’infrastruttura da cui dipende. Tutti i miei AP OpenWrt spediscono metriche e log a uno stack SIEM leggero che gira come quattro container Docker su un Raspberry Pi 5:
- Telegraf – il collector centrale. Scrapa metriche Prometheus dal
node-exporter-luadi ogni AP, riceve syslog dahostapdednsmasq, arricchisce le righe di log tramite un plugin processorexecd, poi instrada le metriche a VictoriaMetrics e i log a VictoriaLogs. - VictoriaMetrics – database time-series per tutte le metriche Prometheus (RSSI, txpower, noise, dati hearing di usteer, nomi stazioni). Leggero, binario singolo, gestisce decine di migliaia di serie su un Pi senza scomporsi.
- VictoriaLogs – storage log per eventi connect/disconnect di hostapd, query DNS, e log dei container Docker. Stessa famiglia di VictoriaMetrics, stessa efficienza.
- Grafana – dashboard e visualizzazione, con il plugin datasource VictoriaLogs per i pannelli log.
Lo stack dipende anche da Technitium DNS che gira come DNS autoritativo e server DHCP della rete. La sua API di reserved leases è ciò che mappa gli indirizzi MAC ai nomi host – il collante che trasforma indirizzi hardware opachi in nomi di dispositivi leggibili in tutta la pipeline.
Il mio sistema di rilevamento presenza originariamente interrogava le metriche tramite questo stack, ma la latenza era troppo alta per il tracking in tempo reale delle stanze – quindi ora scrapa ogni AP direttamente. Lo stack SIEM resta la spina dorsale per l’analisi storica e le dashboard. Scriverò della configurazione SIEM stessa in un post futuro – per ora, sappi che metriche e log fluiscono dagli AP a questo stack, e wifi-dethrash lo interroga.
Lo strumento
Ho costruito wifi-dethrash come una pipeline con quattro componenti:
1. Collector Lua – deployato su ogni AP come collector prometheus-node-exporter-lua. Esporta metriche radio (txpower, canale, frequenza), configurazione UCI wireless (stato 802.11r/k/v, txpower configurata), e dati runtime di usteer (hearing map, eventi roam, carico canale, client associati). Usa nixio per la risoluzione DNS con una cache a livello di modulo per non fare shell out a nslookup ogni 5 secondi.
2. Station Resolver Go – un piccolo binario (cmd/station-resolver) con due compiti. Primo: si piazza nella pipeline Telegraf come processor execd, legge il protocollo Influx line su stdin e arricchisce gli eventi connect/disconnect di hostapd con un campo station=<hostname> risolto dalle reserved leases DHCP. Secondo: serve un endpoint /metrics che espone gauge wifi_station_name{mac, station} 1 che Telegraf scrapa e inoltra a VictoriaMetrics. Questo è ciò che rende la dashboard completamente dinamica – niente mapping MAC-hostname hardcoded, niente re-push della dashboard quando un nuovo device si connette.
3. Analyzer Python – lo strumento CLI wifi-dethrash. Interroga VictoriaMetrics per dati RSSI, noise, e txpower, interroga VictoriaLogs per eventi connect/disconnect di hostapd, poi esegue tre analizzatori: rilevamento thrashing (3+ connessioni alternate tra esattamente 2 AP entro una finestra temporale), analisi overlap RSSI (letture concorrenti dallo stesso client su più AP entro una soglia), e rilevamento associazioni deboli (basso SNR). Infine, il recommender incrocia le coppie di thrashing con i dati di overlap e propone modifiche alla txpower. Controlla anche lo stato 802.11v e segnala gli AP dove manca.
4. Dashboard Grafana – 13 pannelli generati programmaticamente dallo strumento Python, sia come file JSON per l’importazione che pushati direttamente via API Grafana. Tutti gli indirizzi MAC risolti a nomi host dinamicamente via join group_left(station) contro wifi_station_name_gauge.
Flusso dati
[OpenWrt APs]
├─ prometheus-node-exporter-lua ──► Telegraf ──► VictoriaMetrics
│ (wifi_station_signal_dbm, wifi_radio_txpower_dbm,
│ wifi_usteer_hearing_signal_dbm, ...)
│
└─ syslog (hostapd events) ──► Telegraf ──► station-resolver ──► VictoriaLogs
(AP-STA-CONNECTED <mac> auth_alg=ft)
│
└─► /metrics ──► Telegraf ──► VictoriaMetrics
(wifi_station_name{mac,station} 1)
Cosa mostra la dashboard
La dashboard è progettata per rispondere a una domanda: la mia mesh è sana, e se no, perché?
Timeline di roaming
La vista a 3 giorni rende il pattern di thrashing ancora più chiaro – si vede che non è un evento isolato, è un ciclo giornaliero legato al movimento delle persone nella casa:
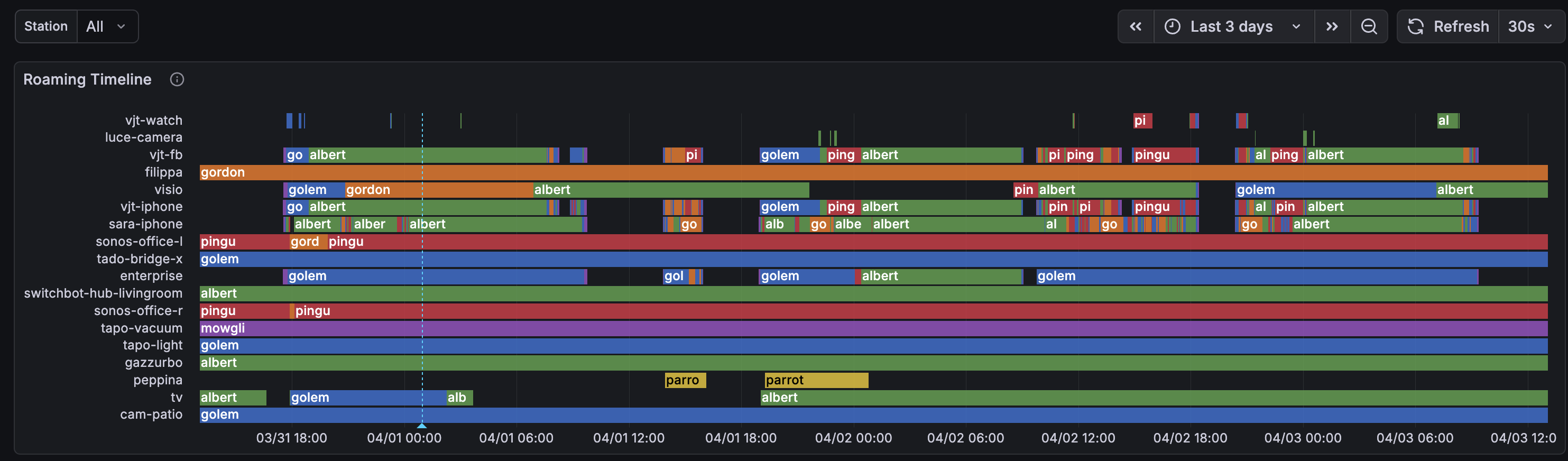
Confronta i telefoni (strisce arcobaleno caotiche) con i dispositivi IoT in fondo – cam-patio, gazzurbo, tado-bridge – barre lunghe e piene, associazioni stabili. Dispositivi stazionari che hanno trovato il loro AP e ci sono rimasti.
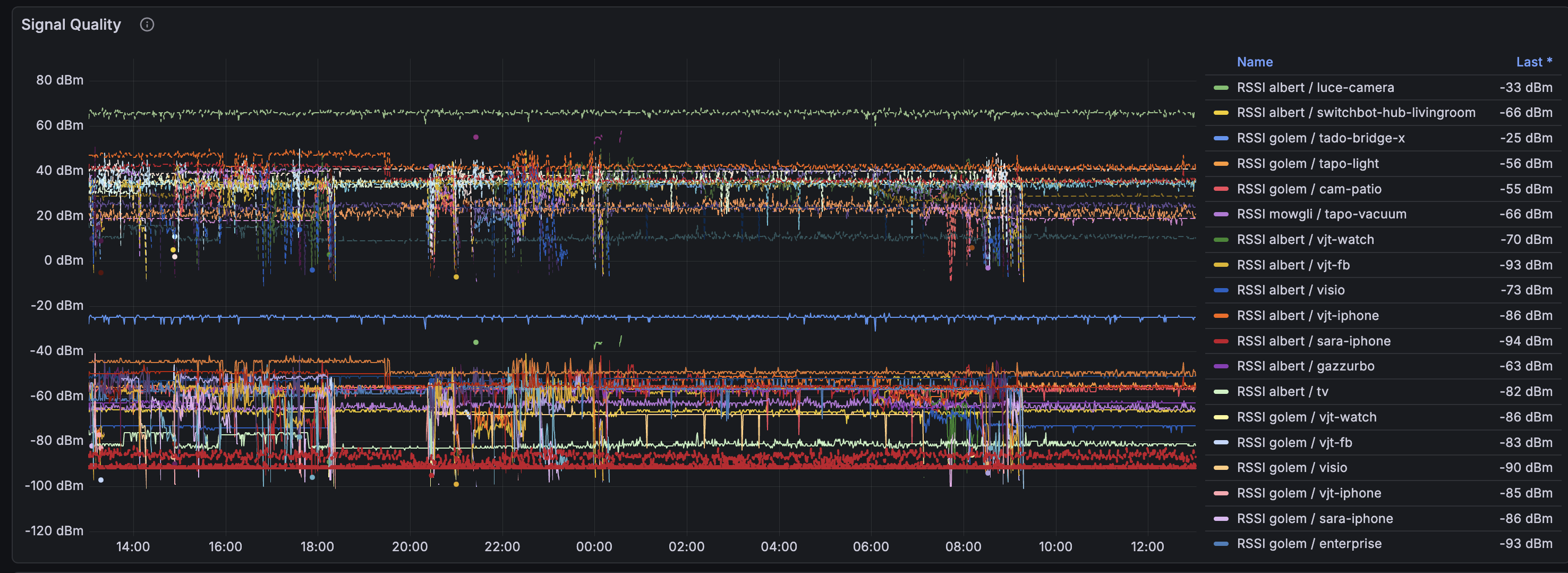
Qualità del segnale
RSSI, SNR, e noise floor per tutte le stazioni. Le linee rosse orizzontali intorno a -90 dBm sono il noise floor. Qualsiasi cosa vicina a quella linea è una connessione marginale.
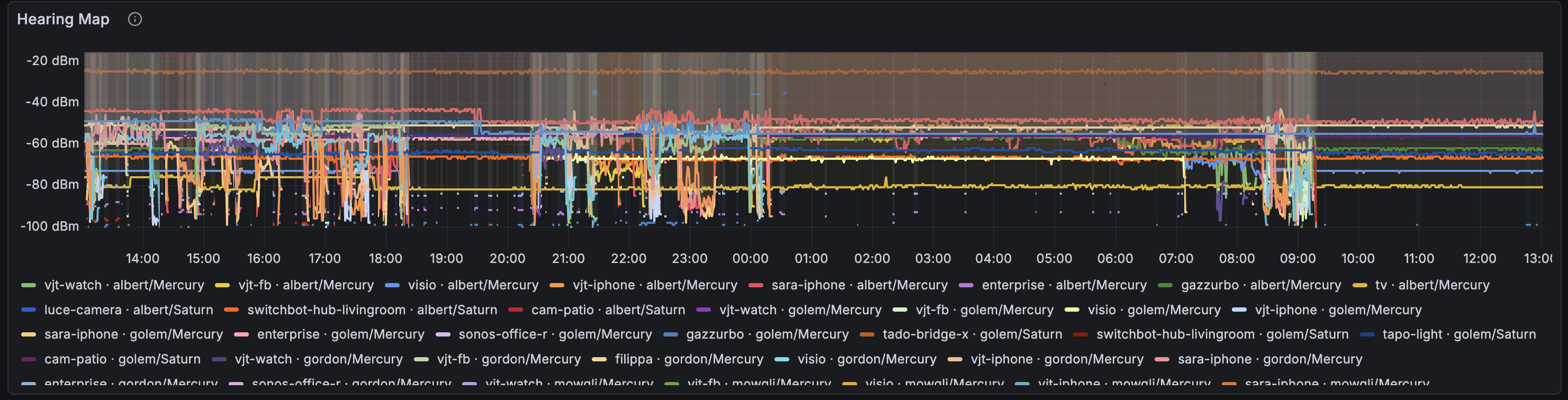
Hearing Map
Questa è la visione del mondo di usteer. Ogni linea mostra quale segnale un AP sente da un client – non solo l’AP a cui il client è connesso, ma tutti gli AP che lo sentono. Quando più linee per lo stesso client sono vicine, quella è una zona di overlap.
Connessioni FT vs Open
Quanti eventi di roaming hanno usato 802.11r Fast Transition (verde) rispetto alla semplice autenticazione open (giallo). I roam FT sono trasparenti – il client si pre-autentica con l’AP target prima di cambiare. Le connessioni open significano che il client è passato per l’associazione completa, che richiede più tempo e può perdere pacchetti.
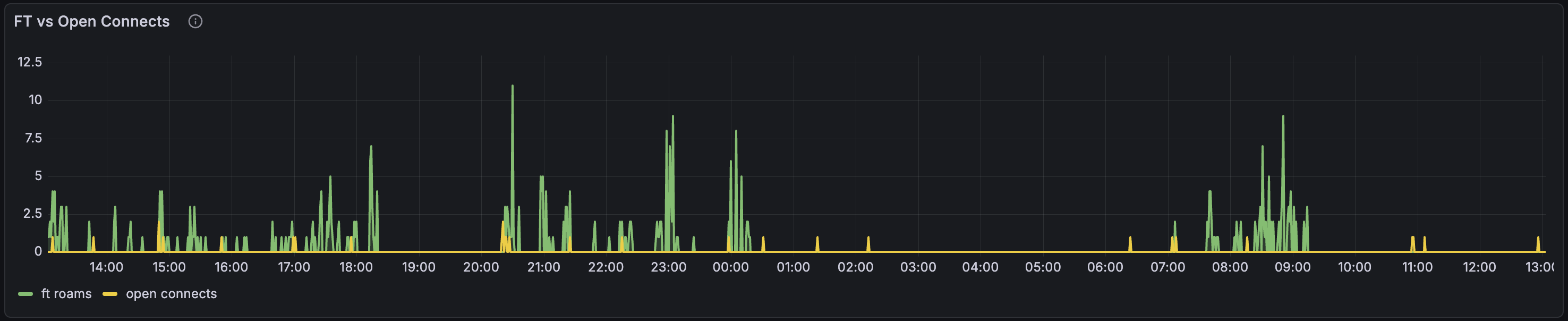
Nel mio caso, l'82% dei roam usa FT – 802.11r funziona. Le barre gialle sono per lo più dispositivi IoT che non supportano 802.11r, e un vecchio AP con OpenWrt 19.07 che non lo supporta nemmeno.
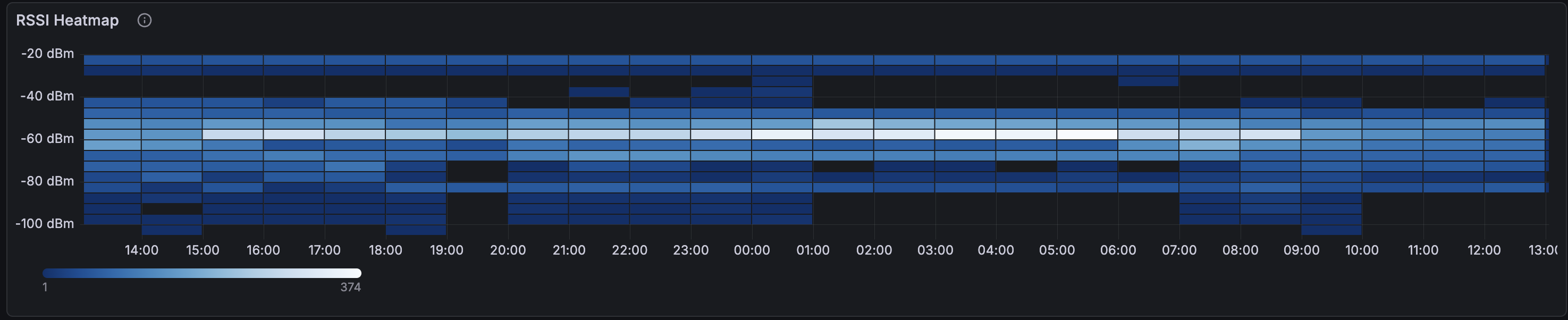
Heatmap RSSI e pannelli di configurazione
La heatmap mostra la distribuzione delle potenze del segnale tra tutti i client nel tempo. La banda luminosa intorno a -60 / -70 dBm è dove vivono la maggior parte delle associazioni. Le bande più deboli sotto -80 sono la zona problematica.
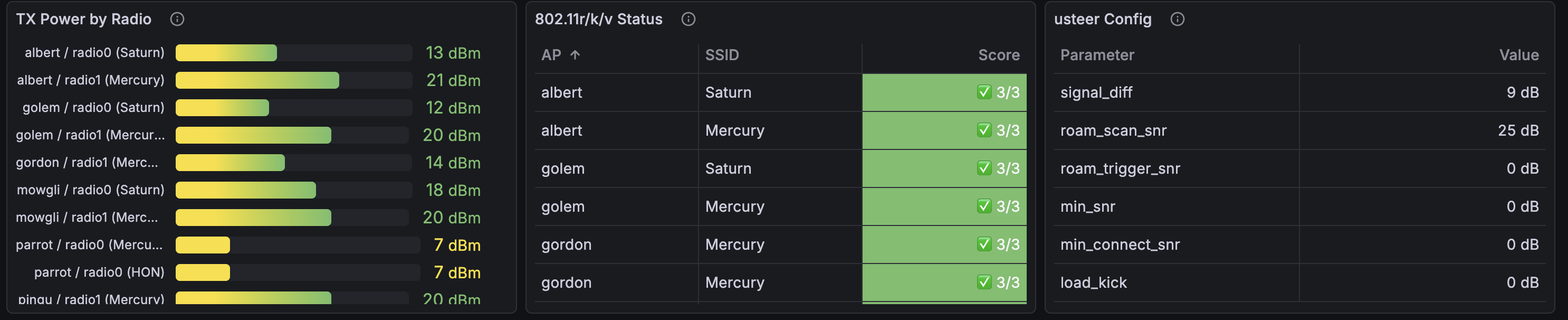
I pannelli di configurazione mostrano la txpower per radio, lo stato 802.11r/k/v, e le soglie di usteer a colpo d’occhio:
L’analizzatore CLI
La dashboard Grafana è per il monitoraggio. Lo strumento CLI è per la diagnosi e l’azione. Eseguendo wifi-dethrash --window 3d si ottiene un report come questo:
Got 120606 RSSI readings, 2202 hostapd events, 19 MAC names.
Thrashing Summary
Station AP Pair Connects Episodes
sara-iphone golem ↔ pingu 103 13
vjt-iphone golem ↔ pingu 29 6
vjt-iphone albert ↔ pingu 11 2
vjt-fb albert ↔ pingu 10 3
...
RSSI Overlap (significant)
Station AP Pair Avg Diff Samples RSSI
sara-iphone golem ↔ pingu 3.4 dB 74/203 -84/-84 dBm
...
Txpower Plan
AP Radio Current → Proposed Delta
pingu radio1 20 dB → 22 dB +2
ssh root@pingu uci set wireless.radio1.txpower=22
usteer Configuration
ssh root@<ap> uci set wireless.<iface>.ieee80211v=1
# Enable BSS Transition Management — required for usteer to send roam hints
ssh root@<ap> uci set usteer.@usteer[0].signal_diff_threshold=9
# Don't roam unless new AP is 9+ dB stronger
...
Incrocia i dati di thrashing con i dati di overlap: una coppia riceve una raccomandazione solo se c’è sia thrashing (i telefoni stanno effettivamente rimbalzando) sia overlap (l’RSSI da entrambi gli AP è abbastanza vicino da causare confusione). Niente falsi positivi.
Il recommender è opinionato. Quando entrambi gli AP in una coppia di thrashing hanno segnale debole (sotto -75 dBm), raccomanda di aumentare la txpower sull’AP con più margine – potenza corrente più bassa significa più spazio per crescere. Esplicitamente non aumenta un AP che è già al massimo. Quando il segnale è sano ma sovrapposto, riduce l’AP più rumoroso per creare differenziazione.
Coordinatori di roaming: usteer, DAWN, e nrsyncd
OpenWrt ha tre opzioni per coordinare il roaming tra AP, e vale la pena capire i compromessi.
DAWN (Decentralized WiFi Controller) è stato la risposta originale. Valuta i client in base a RSSI e carico del canale, e può rifiutare richieste probe/auth/associazione per forzare i client su AP migliori. È stato di fatto abbandonato – l’ultimo sviluppo significativo risale a anni fa, e non funziona in modo affidabile sulle release recenti di OpenWrt. Non vale la pena considerarlo.
usteer ha rimpiazzato DAWN come demone di roaming raccomandato da OpenWrt. Fa sincronizzazione dei neighbor report, condivisione della hearing map, e steering attivo dei client via frame BSS Transition Management (802.11v). In teoria, è la soluzione completa.
In pratica, usteer ha la reputazione di essere inaffidabile. Problemi noti includono: roam_kick_delay che non funziona, channel load steering che non scatta mai, schede WiFi Intel che ignorano completamente le richieste BTM, e report di soft-brick su snapshot recenti di OpenWrt. Il consenso del forum propende per “usteer cerca di fare troppo e non ne fa nessuna in modo consistente”.
nrsyncd adotta l’approccio opposto: distribuisce solo i neighbor report 802.11k tra AP via mDNS. Niente steering, niente kick, niente decisioni di policy. Dà ai client le informazioni di cui hanno bisogno per fare buone scelte di roaming, poi si toglie di mezzo. Leggero, focalizzato, e difficile da rompere.
Cosa sto usando
Attualmente uso usteer, ma con tutte le funzionalità aggressive disabilitate. Le impostazioni chiave:
signal_diff_threshold: fai steering solo se l’AP target è più forte di questo tot di dB. Troppo basso e causi roaming non necessario. Troppo alto e i client restano inchiodati su AP pessimi. Io uso 9 dB.roam_scan_snr: quando l’SNR di un client scende sotto questo valore, usteer inizia a considerare le alternative. Uso 25 dB – scatena la scansione presto senza cacciare nessuno.min_snr/min_connect_snr/roam_trigger_snr: tutti a 0 (disabilitati). Questi cacciano i client sotto la soglia, causando tempeste di disconnessione quando i client sono in zone con copertura debole senza un AP migliore disponibile. Chiedimi come lo so.load_kick_enabled: disabilitato. Disconnettere forzatamente i client sotto carico non è mai la risposta.
La filosofia: usteer dovrebbe suggerire, mai forzare. Usa signal_diff per uno steering gentile, disabilita tutto ciò che caccia.
Ma c’è un prerequisito critico: 802.11v (BSS Transition Management). Senza di esso, gli unici strumenti di usteer sono rifiutare le probe response e bloccare le associazioni – entrambi strumenti rozzi. Con 802.11v abilitato, usteer può mandare frame BTM: educati suggerimenti tipo “ehi, c’è un AP migliore da quella parte” che il client può accettare o ignorare. La maggior parte dei dispositivi moderni (iPhone, Android recenti) rispetta le richieste BTM.
L’analizzatore ora controlla lo stato 802.11v tramite la metrica wifi_iface_ieee80211v_enabled e segnala gli AP dove manca. Era un bug che abbiamo trovato nel nostro stesso setup – usteer era abilitato ma non poteva effettivamente steerare perché 802.11v non era mai stato attivato.
Il verdetto (in sospeso)
Sto dando a usteer un processo equo. Con 802.11v ora abilitato, ha finalmente gli strumenti per fare steering BTM gentile. Se roam_events resta a zero e il thrashing non migliora nella prossima settimana, usteer è peso morto e passerò a nrsyncd – stessa distribuzione dei neighbor report, niente della complessità di steering che non funziona comunque.
Cosa ho imparato
Il roaming WiFi è una decisione del client. L’AP può suggerire, proporre, o rifiutare, ma è lo stack WiFi del client a fare la scelta finale. Gli iPhone sono roamer aggressivi (a volte troppo). I dispositivi IoT si attaccano e non mollano. Le TV LG sono le peggiori – la nostra TV continuava a connettersi a un AP un piano sotto con SNR 14 invece di quello nella stessa stanza con SNR 21. La soluzione? Un cavo ethernet. Alcuni problemi non hanno soluzioni WiFi.
La zona di overlap è dove vive il thrashing. Se due AP hanno una potenza del segnale simile in una data area, i client rimbalzeranno tra di loro all’infinito. La soluzione è o aumentare la potenza di un AP (creare un vincitore chiaro) o ridurre quella dell’altro (restringere la sua copertura). Le raccomandazioni di txpower dello strumento mirano esattamente a questo.
I dati battono l’intuizione. Pensavo che la mia mesh fosse a posto perché “funziona.” La dashboard ha mostrato il contrario: 129 eventi di roaming, 73 rimbalzi, 15 transizioni avanti e indietro in 2 minuti per un singolo telefono. Non puoi fare debug di quello che non puoi vedere.
Stato attuale
Siamo in modalità osservazione. Modifiche recenti:
- Aumentata la txpower a 5 GHz di un AP da 18 a 20 dBm per migliorare la copertura nella zona di overlap
- Abilitato 802.11v su tutti gli AP così usteer può mandare frame BTM
- Sistemato il recommender per fare suggerimenti di txpower più intelligenti
- Collegata la TV via cavo (100 Mbit ethernet batte un WiFi traballante qualsiasi giorno)
La timeline di roaming a 3 giorni mostra che il pattern è ancora presente ma potenzialmente in miglioramento. Servono più dati.
Provalo
Il progetto è su github.com/vjt/openwrt-dethrash. Ti servono:
- AP OpenWrt con
prometheus-node-exporter-lua - Una pipeline VictoriaMetrics + VictoriaLogs + Telegraf
- Grafana con il plugin datasource VictoriaLogs
- Python 3.12+ per lo strumento CLI
- Opzionalmente, Technitium DNS per la risoluzione MAC basata su DHCP
Il collector Lua, il station resolver Go, e l’analyzer Python sono tutti nel repo. La dashboard è generata programmaticamente – wifi-dethrash --push-dashboard crea tutti i 13 pannelli con gli UID datasource corretti. Le metriche sono documentate nel CLAUDE.md.
Happy hacking!