On July 22nd 2010, Mikamai hosted a Ruby Social Club in
Milan, where
nearly 50 people attended watching five speeches about Ruby, Web development
and Startups. I was glad to be one of the speakers, and I presented a set of
Rails plugins we spinned off from our latest (and
greatest) project: Panmind (read more on the about
page) and released as Open Source on
GitHub.
The keynote is split in two parts: the first one explains why you should
follow the sane software engineering principle of writing modular and
interest-separated code and then how you could (and should) extract it from
your Rails application by decoupling configuration and then prepare for the
Open Source release, by writing documentation AND presenting to a Ruby
event so, hopefully, someone else will write unit tests! :-)
We released an SSL helper plugin that
implements filters (like Rails’ ssl_requirement) but also named route helpers:
no more <%= url_for :protocol => 'https' %>! You’ll have something like
plain_root_url and ssl_login_url - like they were built into the framework.
Then, a Google Analytics ultra-simple
plugin, with <noscript> support, a couple of test helpers and an
embryo
of a JS Analytics framework - hopefully it’ll evolve into a complete jQuery
plugin. Then, a ReCaptcha interface,
with AJAX validation support and eventually a
Zendesk interface for Rails.
As most of you already know, there are two open, critical
vulnerabilities in iPhone
OS versions from 3.x up. The first one resides in the Compact Font Format
component of the PDF renderer and the second one an error in the kernel,
allowing attackers to bypass the sandbox (SeatBelt) inside which applications
are run on the iPhone.
The two vulnerabilities were discovered by @comex,
@chpwn and other people.
Only few weeks later the .lnk design
flaw on windows (guys, you’re using
LoadLibraryW to load a damn icon!), these iPhone OS vulnerabilities are even
more interesting, because of the way the release is being handled by the
community and the vendor.
I spent 3 hours last night trying to find detalied information about the bug,
and except confused (and propagandistic) blog posts the only bit of
information is in this tweet,
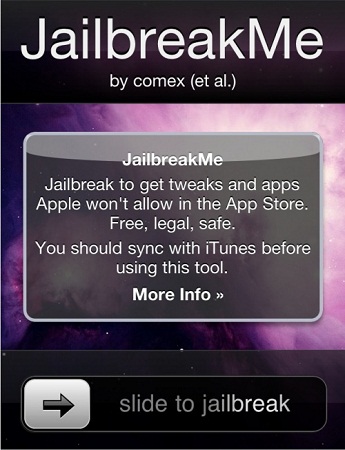
and in the actual pdf exploit running on
jailbreakme.com. Where are the security lists
posts? Where is the CVE? Even the CERT still doesn’t say anything about this
vulnerability.
There’s something terribly wrong going on: the
cat-and-mouse-game that is making
the iphone-dev team researchers not disclose any
of the vulnerabilities they find has become very dangerous for end users: an
exploit that allows remote code execution and jail escape without no
interaction whatsoever by the user, carried via something that’s used to
consider “safe” (a PDF file) is what is called a critical hole; while the
exploit that uses it is called a 0-day. It’s the first time in my life I see
a 0-day packaged and distributed explicitly via a web site.
In a nutshell, it adds support for unmarshaling 1.9 strings, and implements the
last missing type (TYPE_LINK) that was missing from the code. Tests still
lack, can someone help ? :-)
Added TYPE_LINK, needed because of how ruby 1.9 marshals strings.
In 1.9, Ruby marshals the string encoding in the binary output, and
uses an Ivar construct (TYPE_IVAR) to wrap the string and adds an
"encoding" instance variable (notice: without a leading @) whose
value is the encoding itself.
While the Ivar code worked correctly, the values of the encodings
are actually *strings*, that are being reused via the TYPE_LINK
construct, that wasn't implemented.
So, the get() and put() primitives are being used to store not
only tuples {id, sym} for symbols, but now store either
{{symbol, ID}, sym}
OR
{{value, ID}, val}
for the other types that use TYPE_LINK.
By reading the ruby marshal.c source code, it looks like that MANY
data types save their values in the arg->data hashtable, but by
inspecting the binary marshal output of, e.g, an array of floats,
links aren't used.
Thus, in this unmarshaler, links are considered, for now, only for
strings and regexes.
If your CouchDB 0.11 gives you the “Invalid UTF-8 JSON” error on every POST
or PUT you issue to it, make sure that in your
$prefix/usr/lib/couchdb/erlang/lib there aren’t leftovers from previous
installations.
On our dev server, I found there two directories
(“couch-0.10” and “mochiweb-r97”) from the old 0.10 setup that were causing
this issue.
This applies if you upgraded from source, as you’ve probably did, because there
aren’t too many packages of CouchDB 0.11 as of April 2010 :-).
From the stage of web2.0 Expo 2008 in San Francisco, Clay
Shirky talks about the social revolution carried by
web2.0 into contemporary society, from TV to Wikipedia and World of Warcraft.
And twitter still had to be globally recognized, in 2008.
Original video file and related discussion here
(courtesy of blip.tv). Score: 5 (insightful)
For those who understand italian, I’ve just published
an article on therubymine.com on the
upcoming Ruby on Rails framework release,
version 3.0: the big news is the merger with another ruby web framework, merb.
The sad conclusion: “humans are such herd animals”
The good conclusion: “virality has always existed, it’s not an invention
of Web2.0. Social networking is just a powerful tool for everyone that wants to
change the world”
The mean conclusion: “how much does it take to get people from their
computers to the real world after a virtual ‘heads up’ by some ‘dancing man’?”
Take the whole social environment, utterly unprepared to the media \(r)evolution happening in the last years, and let the hackers observe and talk/write about it. Bring in the lawyers, and let them recognize that “Houston! We’ve got a problem!”, whilst also they define it via lawspeak. Ask questions, and participate to interesting debates.
Now, deliver the 2007 big brother award to the Google Representative, let the sun dive in the hills, add a noticeable amount of Tuscany red wine, and get ready for the next day. Let the paranoia flow, while the hackers show how you can be traced and found via the cellular network and spied via wifi-networked cameras placed there for your safety.
We’re connected. We’re utterly connected. We’re sharing, we’re creating multiple identities, we’re exaggerating and becoming addicted, we’re earning money (maybe) from it, and if on one side we’re opening our minds to different cultures and points of view, on the other we’re just narrowing our visions because we find only the informations we search for, treating the Internet as a soft surrogate of the TV, annihilating critical thought, and even worse, demonizing the ‘net (not in the unix meaning of the term) because of the statements of some «politicians», forgetting that everything men have built in history are tools, and any problem tools cause it’s just a matter of how other men actually use them, not the tools themselves.
Of course kill 222 ; pppd call dsl-provider doesn’t work. YUCK. Let’s put a router in front of it.. configure, portforward, and start over.. then fdisk /dev/hdc to recreate partitions structure on the new hard disk, mkfs.xfs on all the new partitions, mount /dev/hdcX /target, pax -r -w -p e /{bin,boot,dev,etc,home,initrd,lib,media,root,sbin,srv,tmp,usr,var} /target… wait a lot for the copy to complete because of damaged sectors on the source hard disk, chroot /target, vi /etc/lilo.conf and substitute boot=/dev/hda with boot=/dev/hdc, run lilo -v while in the chroot verify /etc/fstab, and finally shutdown to remove the faulty disk, and boot again.. restoring lilo.conf. yay!
«Women! The knife grinder is here!» – Apart from funny jokes ;) the italian Apple Store together with Girl Geek Dinners Roma organized on May 16, 2009, a workshop about mobile lifestyle (focusing on the iPhone, of course).
Let’s start from the beginning: what are the Girl Geek Dinners? Linda explained to the audience (nearly 20 people) that a geek is a person passionate about technology in a broader sense: the GGD is a group devoted to aggregate women interested about the internet, new medias and technologic lifestyles. Women are often underestimated in geek communities, and this embarassing clichè generated a lot ofdiscussion in the past, and it’s still unsolved (in my opinion).
The GGD italian group was born in 2007 in Milan, and then arrived to Rome in 2008, and is also present in Bologna and in the Marche and Emilia-Romagna states.
So, the GGD group tries to generate a “critical mass” of geek women, to abolish a stereotype that “computer programmers / power users” are only men: in GGD events boys listen and girls talk, then they blog, exchange vCards (and PGP keys, I’d guess ;) and in general try to harness women power and skills in the field of the computer industry. Networking and a dive into social media is the most efficient way nowadays to reach a great audience, and to build rapidly the aforementioned critical mass: that’s why the GGDs event was focused on social mobile applications and general productivity ones. Presented by two official Apple Trainers (Simona and Riccardo), the workshop started @11.30 AM and lasted nearly one hour.